先別問該買哪個 AI:2026 品牌行銷 AI 獲利配方裡,資料是 80%


給每位糾結 ChatGPT vs Claude vs Gemini vs 各種 LLM 的零售品牌主,一個更該先問的問題
該買 ChatGPT 還是 Claude?答錯了起點
零售品牌主這幾季最常問我的一個問題,是「該買 ChatGPT 企業版還是 Claude,哪一個對我家業績幫助大?」
這是好問題,但答錯了起點。
即使把三家主流模型都買齊,會員資料庫沒整理過、自動化腳本沒搭起來、行銷流程沒拆給 AI 接手,業績不會自己長出來。問錯問題的人,買到對的工具也得不到對的答案。
更尷尬的對比是這樣的:很多品牌把今年 AI 預算的 80% 砸在模型訂閱、20% 給資料整理、幾乎沒給自動化系統,然後抱怨 AI 沒效果。
這件事本來就會變這樣。
本文要提出一個 2026 年台灣零售現場的經驗法則
Brand AI Outcome = Data × Harness × Model
重要性權重:Data 80% / Harness 15% / Model 5%
這個比例適用於多數品牌的 CRM、會員分群、內容生成、廣告投放、客服回應場景。以下幾類零售場景例外,模型或自動化權重會上升:金融、醫療這類法規敏感領域;科學運算、影音生成這類重多模態場景;新品牌冷啟動(資料量不足);低頻高單價商品(行為樣本稀少);創意驅動品牌(風格主導大於資料);法遵限制嚴格(個人化空間受限);跨境多市場資料碎片化未歸戶。
但對絕大多數零售品牌而言,AI 沒長出業績的理由,藏在那 80% 的 Data,不在 5% 的 Model。
拆開來看:Data 80% / Harness 15% / Model 5%
把 AI 在品牌行銷的成效拆成三層,會比較容易看出問題出在哪。
Layer 1:Data(資料),重要性 80%:客戶畫像(客戶是誰、買過什麼、什麼時候流失、為什麼回購、在 App 點過哪些品類)。乾淨的資料是 AI 能精準推薦、寫對文案、算對 LIFT 值的前提。
Layer 2:Harness(基礎設施),重要性 15%:自動化腳本、分群框架、觸發條件、效果追蹤。會員註冊自動發 welcome、消費滿額自動升級、超過 30 天沒回購自動催購。沒有這層,AI 寫得再好的文案也是一次性。
Layer 3:Model(模型),重要性 5%:主流模型(GPT、Claude、Gemini)在多數零售情境下表現差距比想像小,LMSys 公開的 Chatbot Arena 顯示前段班模型 Elo 差距有限。
整理成一張對比表:
| 層級 | 是什麼 | 重要性權重 | 預算建議 | 為什麼這個權重 |
|---|---|---|---|---|
| Data | 客戶畫像、行為軌跡、跨通路 ID | 80% | 60-70% | 髒資料污染下游所有應用 |
| Harness | 自動化腳本、分群框架、觸發追蹤 | 15% | 20-30% | 沒它,AI 寫得再好都是一次性 |
| Model | 主流 LLM 訂閱(GPT/Claude/Gemini) | 5% | 5-10% | 主流模型差距比想像小 |
模型不是不重要,但在 Data 還沒乾淨、Harness 還沒搭起來之前,糾結用哪個模型,就像爭論該開特斯拉還是保時捷,但車庫裡連油都沒加。
注意,重要性權重和預算分配比例不一樣。預算建議多出來的部分是固定成本與系統啟動的最低門檻效應,不是這層真的更重要。一份模型訂閱的最低費用,往往跟資料工程師一個月薪水比起來低很多,但需要的人力與時間,又比模型訂閱多得多。
兩個提醒:第一,80/15/5 是注意力與成效敏感度的排序,不是精密的因果歸因。零售業績還受 offer 設計、商品力、渠道成本、組織採用率、執行節奏的影響。這個框架想做的事,是校正多數品牌「先看模型再看資料」的習慣性錯位,並沒有否認其他變數。第二,80/15/5 是成效敏感度,60-70 / 20-30 / 5-10 是年度投資配比,兩者不必一一等比對映。
三個案例:誰把資料當資產,誰把資料當垃圾
案例一:Klarna 的 AI 客服替代風波
2024-02 瑞典金融科技公司 Klarna 公開稱,AI assistant 承擔了約 700 名全職客服的工作量。這個故事在媒體上被傳成「AI 取代人」的標準範例。一年多後的 2025-05,Klarna CEO 又公開強調 human support 品質的重要性。
這個故事很少被提的部分,是 Klarna 在那 700 人替代背後,花了好幾個月做客服資料的整理:問題分類、SOP 標準化、客戶歷史串接。沒有這層資料治理,AI 客服連第一通電話都接不好。
案例二:The New York Times 的訂閱資料策略
NYT 是這幾年公認玩第一方訂閱資料玩得最好的媒體公司。NYT 官方文件顯示,其以 proprietary first-party data 支援廣告與成長業務。NYT 知道訂閱戶的閱讀軌跡、停留時長、跨主題興趣,這些資料訓練出來的個人化推薦,是別家媒體就算砸再多錢也買不到的。
當其他媒體還在跟廣告 cookie 拼第三方數據,NYT 把第一方訂閱資料當主戰場經營。
案例三:常見的台灣零售場景
更貼近台灣品牌的場景是這樣的。
客戶 A 早上在官網下單一支保濕乳液、中午到門市自取、下午在 LINE OA 領了一張下次回購折扣券、晚上又在 App 看了同品牌的化妝水。
這四筆行為散在四個系統,AI 看到的是四個人,老闆心裡知道是同一個人。
這個落差就是護城河蓋不起來的地方。下游所有應用都會被這個落差污染:分群會把同一人切成四群、推薦會把已買過的乳液再推一次、文案會用錯個人化欄位、廣告投放會浪費預算在重複建檔的客戶身上。
案例四(反例):Cookies 沒落與第三方資料的崩塌
Google 從 2020 年開始喊第三方 Cookie 要退場,期間延期改口三次,2025-04 最新立場是維持目前的第三方 Cookie 選擇機制、不再推新的獨立提示,Privacy Sandbox API 路線仍在調整。即使最終時程持續延後,第三方資料的長期不確定性已被市場確認。對品牌主來說,意涵不在「Cookie 還在所以可以繼續用」。重點是第一方資料的相對價值,這幾年正在上升。
為什麼 Data 是 80%
這個比例聽起來偏激,但拆解就好懂了。
表象:AI 寫不出好文案、推薦不準、投放浪費預算、客服回應失準。
機制:髒資料會污染下游所有應用。同一人在系統裡有三張卡,分群就把他切成三群;缺值沒處理,文案就用錯個人化欄位;缺跨平台 ID,廣告就把預算投在重複建檔的人身上。
最深的那層:模型是免費的競爭力,資料是付費的護城河。
模型誰都能買,競爭對手也訂閱,明年大家都會用更便宜更強的版本。但你十年累積的客戶行為資料,是別人花再多錢買不走的。能成為真正資產的,是要花錢花時間慢慢養的東西。
這個邏輯在 Cookie 退場後被進一步放大。第三方資料的時代結束,第一方資料的相對價值上升。當競爭對手不再能用第三方 Cookie 補齊資料、只能仰賴自己的第一方資產時,你十年累積的會員行為資料的市場稀缺性,會被市場重新計價。
對台灣零售品牌來說,這代表兩件事:
第一,過去用「廣告投放優化」蓋的競爭優勢,2026 年正在貶值。
第二,過去覺得「老掉牙」的會員資料庫,正在升值。
這正是資料治理層存在的理由。沒有它,第一方資料只是一堆散在不同系統的欄位,不是資產。
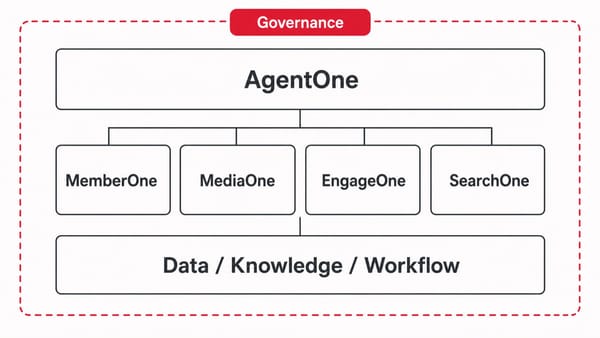
CDMP 在這場遊戲裡扮演什麼角色
如果 AI 是放大器,給它什麼放大什麼,那 91APP CDMP 就是負責讓「給它的東西」變優質的角色。
有優質數據 input,才有優質答案 output。
具體拆成三件事:我們以91APP CRM 及 CDMP 常用分群方式來做範例
第一件:UCP(Unified Customer Profile,統一客戶輪廓)
把客戶在官網、App、門市 POS、LINE OA 的行為,串成一個人。前面那個「客戶 A 早上下單、中午自取、下午領券、晚上看化妝水」的場景,在沒有 UCP 之前是四筆資料、四個人。在 UCP 之後是一個人、四個行為節點,AI 看到的是完整的客戶旅程,不是四個碎片。
第二件:NAPLRS 生命週期框架
分群維度不是性別、年齡、縣市,而是「他在你品牌的哪個階段」。註冊未購、新客、主力客、流失中、沉睡客。每個階段的客戶,想對他講的話完全不一樣。
把分群從人口屬性轉到生命週期,AI 才有辦法針對「現在的他」生成內容,不是針對「人口統計上的他」。
第三件:DCIU 購買意圖標籤
D(Dormant)/ C(Curious)/ I(Intent)/ U(Urgent)。讓 AI 看到的,是「這個人現在處於什麼購買意圖階段」。對 Curious 階段的人推折扣券會浪費預算,對 Urgent 階段的人推教學內容會錯過時機。資料告訴 AI 該做什麼,AI 才有辦法做對的事。
這三件事的共同點:把第一方資料從「一堆欄位」變成「可以被 AI 拿來用」的資料工程。
CDMP 在這個架構裡的位置,是讓 Layer 1 的 Data 從口號變成可執行的工程層支點。
五個明天可以開始的動作
不要先跑 ChatGPT,先做這五件事。
| # | 行動 | 做法 | 預期效果 | 建議週期 |
|---|---|---|---|---|
| 1 | 盤點你擁有的資料 | 列清單:客戶基本檔、訂單、行為軌跡、互動紀錄分別在哪幾個系統,格式統一嗎 | 一個下午,所有 AI 應用的起點 | 1 天 |
| 2 | 定義「乾淨」的具體標準 | 必填欄位(哪 5 個必填)、命名規則、缺值處理、去重規則、跨平台 ID 怎麼串 | 兩個會議,從「也許可用」變「可分群可預測」 | 1 週 |
| 3 | 建立會員生命週期框架 | 用 NAPLRS 五階段分群(註冊未購、新客、主力客、流失中、沉睡客) | 一個策略會議,後續行銷溝通的骨架 | 1 週 |
| 4 | 先設計流程,提示詞再說 | 拆出工作流程,標出哪段交給 AI、哪段留給人。例如客服第一輪給 AI、複雜申訴留人;商品文案初稿給 AI、品牌調性審稿留人 | 一張流程圖,AI 從玩具變生產線 | 2 週 |
| 5 | 預算分配重新洗牌 | 60-70% Data、20-30% Harness、5-10% Model | 一次年度重審,未來 12 個月不做白工 | 1 次 |
幾個提醒:
動作一的「列清單」很多人覺得不重要,但這是後續所有動作的地基。沒有這份清單,動作二根本不知道要清哪幾張表。
動作三的 NAPLRS 是會員生命週期分群的常見方法論之一。你不一定要用一樣的命名,但生命週期分群的邏輯是必要的。性別年齡分群在 AI 場景下產出極有限。
動作五最反直覺。多數品牌的本能是把預算押在「最性感的那個」,模型訂閱新聞每週都在發、會員資料工程沒有新聞稿。但反過來分配,才會在 12 個月後看到差別。
結論:那台沒加油的保時捷
如果你今天讀這篇文章是因為糾結要不要訂 GPT-5 的最新版本、要不要試 Claude 4.7、Gemini 3 比較好還是不好,那答案大概是:先別。
先看資料,再看流程,最後才看模型。
這個順序,是這篇文章想留下的唯一一句話。
台灣零售品牌十年累積的 OMO 會員資料,是別人花再多錢買不走的。前提是你願意先花一個下午去盤點它、花一週去定義它的乾淨標準、花一次預算重審把它放回應該被重視的位置。
那台車庫裡的保時捷,現在去加油都還來得及。
品牌最常問的「AI 獲利配方」問題
Q1:為什麼是 Data 80%、Model 5%,這比例怎麼來的?
A:本文提出的目的是讓品牌主重新思考預算與注意力分配的優先順序。涉及金融、醫療、科學運算、影音生成的場景,模型權重會更高。但對 CRM、會員分群、內容生成、廣告投放、客服這類零售場景,Data 才是決定 AI 產出品質的關鍵變數。
Q2:Data 80% 跟以前說的「資料庫行銷」有什麼不同?
A:差在三件事。第一,資料庫行銷時代分群維度是性別年齡縣市,現在是生命週期與購買意圖。第二,資料庫行銷的資料只在自家系統,現在要跨官網、App、門市 POS、LINE OA 串起來。第三,資料庫行銷的下游應用是 EDM 名單,現在的下游應用是 AI 模型,對資料品質的容忍度更低。
Q3:預算有限的品牌也要先做資料治理嗎?
A:是。預算越有限,越不該把錢押在模型訂閱。一份 GPT 企業版訂閱與一週的資料盤點時間,後者對小品牌的長期價值大很多。沒有資料工程團隊的小品牌可以從動作一(盤點)和動作三(NAPLRS 分群)做起,這兩件事用 Excel 就能開始。
Q4:資料乾淨化大概多久能看到 AI 應用的差別?
A:依品牌資料現狀差異很大。前提是已具基本會員資料結構、團隊有 1-2 位資料負責人。在這個前提下,做完動作一到動作三,大約 4-8 週可以在 EDM 開信率、推薦點擊率看到改善(目標先做粗分群,不追求即時自動化)。如果原本資料散在多個系統,整合工程會拉長到 3-6 個月。
Q5:沒有資料工程團隊的品牌怎麼開始?
A:兩條路。第一條是內部自盤,從動作一(列清單)做起,這不需要工程能力。第二條是找有 CDMP 服務能力的合作夥伴,把跨系統資料串接、UCP 建立、生命週期分群這些工程外包,自己保留策略決策。
Q6:是不是把資料丟給 AI 它就會自動變乾淨?
A:不會。AI 是放大器,給它什麼放大什麼。髒資料丟給 AI,產出的是更精緻的垃圾。文案會更像文案、報表會更像報表,但錯誤也會更像正確答案。資料品質永遠是上游問題,不能委外給下游解決。